A Simple Solution for Offline Imitation from Observations and Examples with Possibly Incomplete Trajectories
Kai Yan, Alexander G. Schwing, Yu-Xiong Wang
Conference on Neural Information Processing Systems (NeurIPS), 2023
New Orleans, Louisana, United States
PDF | Code | Poster | Slide | Bibtex
{kind=link}
"Existing methods for offline Imitation Learning from Observation (LfO) are not robust enough.
Is there a simpler and more robust solution?"
Performance
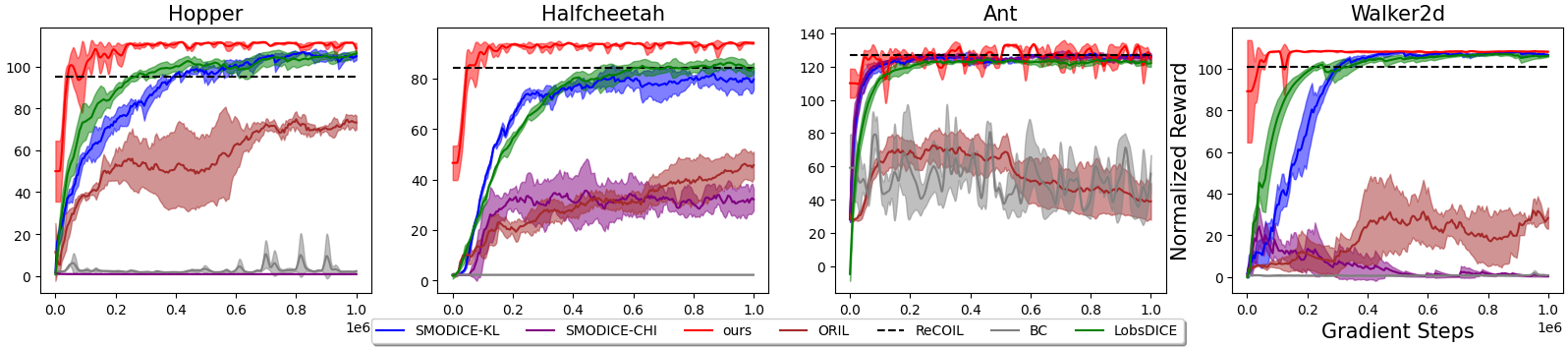
Our method excels across a variety of scenarios and outperforms many methods, including SMODICE [1], LobsDICE [2], ORIL [3], MOReL (with extra access to reward) [4], MOPO (with extra access to reward) [5], ReCOIL [6], OTR [7], DWBC (with extra access to expert action) [8], MARWIL [9], RCE [10], and behavior cloning.
With Standard Settings in SMODICE [1]
Vs. SMODICE [1], LObSDICE [2], behavior cloning, ORIL [3], ReCOIL [6]
Vs. OTR [7], DWBC with expert action [8] and MARWIL [9]

With Few Expert Trajectories in the Task-Agnostic Dataset
Vs. SMODICE [1], LObSDICE [2], behavior cloning, ORIL [3], ReCOIL [6]

Vs. OTR [7], DWBC with expert action [8] and MARWIL [9]

With Incomplete Task-Agnostic Dataset

With Incomplete Task-Specific Dataset

Example-Based Imitation

Transfer from Different Dynamics

Standard Offline RL Benchmarks
Note our method has no access to the ground-truth reward label, which is different from the baselines.| Environment | MOReL [4] | MOPO [5] | TAILO (Ours) |
|---|---|---|---|
| Halfcheetah-Medium | 42.1 | 42.3 | 39.8 |
| Hopper-Medium | 95.4 | 28 | 56.2 |
| Walker2d-Medium | 77.8 | 17.8 | 71.7 |
| Halfcheetah-Medium-Replay | 40.2 | 53.1 | 42.8 |
| Hopper-Medium-Replay | 93.6 | 67.5 | 83.4 |
| Walker2d-Medium-Replay | 49.8 | 39.0 | 61.2 |
| Halfcheetah-Medium-Expert | 53.3 | 63.3 | 94.3 |
| Hopper-Medium-Expert | 108.7 | 23.7 | 111.5 |
| Walker2d-Medium-Expert | 95.6 | 44.6 | 108.2 |
| Average | 72.9 | 42.1 | 74.3 |
See our original paper for a thorough ablation study of our method (and DICE methods [1, 2]).
Abstract
Offline imitation from observations aims to solve MDPs where only task-specific expert states and task-agnostic non-expert state-action pairs are available. Offline imitation is useful in real-world scenarios where arbitrary interactions are costly and expert actions are unavailable. The state-of-the-art `DIstribution Correction Estimation’ (DICE) methods minimize divergence of state occupancy between expert and learner policies and retrieve a policy with weighted behavior cloning; however, their results are unstable when learning from incomplete trajectories, due to a non-robust optimization in the dual domain. To address the issue, in this paper, we propose Trajectory-Aware Imitation Learning from Observations (TAILO). TAILO uses a discounted sum along the future trajectory as the weight for weighted behavior cloning. The terms for the sum are scaled by the output of a discriminator, which aims to identify expert states. Despite simplicity, TAILO works well if there exist trajectories or segments of expert behavior in the task-agnostic data, a common assumption in prior work. In experiments across multiple testbeds, we find TAILO to be more robust and effective, particularly with incomplete trajectories.
Why is Current State-of-the-Art Non-Robust?
The current state-of-the-art method for LfO, SMODICE [1] and LobsDICE [2], optimizes policy by maximizing the dual of KL-divergences between learner and expert state(-pair) occupancies, which has a linear \(V(s)\) term and \(\exp(R(s)+\gamma V(s')-V(s))\) or \(\exp(c(R(s,s')+\gamma V(s')-V(s)))\), where \(R\) is a reward learned by a discriminator, and \(V(s)\) is the (equivalence of) value function. If the task-agnostic dataset is incomplete, some terms will be missing from the objective, which in turn will lead to divergence in training.
Illustration of Divergence
Red corresponds to term missing; training ends early due to NaN.
The DICE method is also known for struggling on incomplete task-specific (expert) datasets due to overfitting [11] and lack of generalizability [12, 13], and \(\chi^2\)-divergence-based variants are generally even weaker than KL ones. See our paper for a more rigorous and detailed discussion.
What is Our Solution?

Our solution is very simple: Improve the reward-labeling process of DICE methods [1, 2], and remove the value function learning process that is non-robust.
Improved reward-labeling: DICE methods train a normal binary discriminator with states from task-specific data as positive samples and states from task-agnostic data as negative ones. However, considering the fact that there are expert segments remaining in the task-agnostic data, we use a 2-step Positive-Unlabeled (PU) learning, seeing task-agnostic data as unlabeled dataset, to achieve better classification margins.
Non-parametric weights for behavior cloning: with reward for each state labeled, we use the discounted sum of thresholded (exponentiated) future reward as the coefficient for each state-action pair in the task-agnostic dataset. Such objective allows rewards to be propagated along the trajectories that leads to expert trajectories, decaying after deviating from expert trajectory segments, while removing the need of learning value functions, which is a major source of instability. Such weight is also robust to missing steps along the trajectory, and it does not need to be very accurate.
Related Work
[1] Y. J. Ma, A. Shen, D. Jayaraman, and O. Bastani. Smodice: Versatile offline imitation learning via state occupancy matching. In ICML, 2022.
[2] G. hyeong Kim, J. Lee, Y. Jang, H. Yang, and K. Kim. Lobsdice: Offline learning from observation via stationary distribution correction estimation. In NeurIPS, 2022.
[3] K. Zolna, A. Novikov, K. Konyushkova, C. Gulcehre, Z. Wang, Y. Aytar, M. Denil, N. de Freitas, and S. E. Reed. Offline learning from demonstrations and unlabeled experience. In Offline Reinforcement Learning Workshop at NeurIPS, 2020.
[4] R. Kidambi, A. Rajeswaran, P. Netrapalli, and T. Joachims. Morel: Model-based offline reinforcement learning. In NeurIPS, 2020.
[5] T. Yu, G. Thomas, L. Yu, S. Ermon, J. Y. Zou, S. Levine, C. Finn, and T. Ma. Mopo: Model-based offline policy optimization. In NeurIPS, 2020.
[6] H. S. Sikchi, A. Zhang, and S. Niekum. Imitation from arbitrary experience: A dual unification of reinforcement and imitation learning methods. ArXiv:2302.08560, 2023.
[7] Y. Luo, Z. Jiang, S. Cohen, E. Grefenstette, and M. P. Deisenroth. Optimal transport for offline imitation learning. In ICLR, 2023.
[8] H. Xu, X. Zhan, H. Yin, and H. Qin. Discriminator-weighted offline imitation learning from suboptimal demonstrations. In NeurIPS, 2022.
[9] Q. Wang, J. Xiong, L. Han, H. Liu, T. Zhang, et al. Exponentially weighted imitation learning for batched historical data. In NeurIPS, 2018.
[10] B. Eysenbach, S. Levine, and R. Salakhutdinov. Replacing rewards with examples: Example-based policy search via recursive classification. In NeurIPS, 2021.
[11] A. Camacho, I. Gur, M. Moczulski, O. Naschum, and A. Faust. Sparsedice: Imitation learning for temporally sparse data via regularization. In the Unsupervised Reinforcement Learning Workshop in ICML, 2021.
[12] T. Xu, Z. Li, Y. Yu, and Z.-Q. Luo. On generalization of adversarial imitation learning and beyond. arXiv preprint arXiv:2106.10424, 2021.
[13] L. Ziniu, X. Tian, Y. Yang, and L. Zhi-Quan. Rethinking valuedice - does it really improve performance? In ICLR Blog Track, 2022.